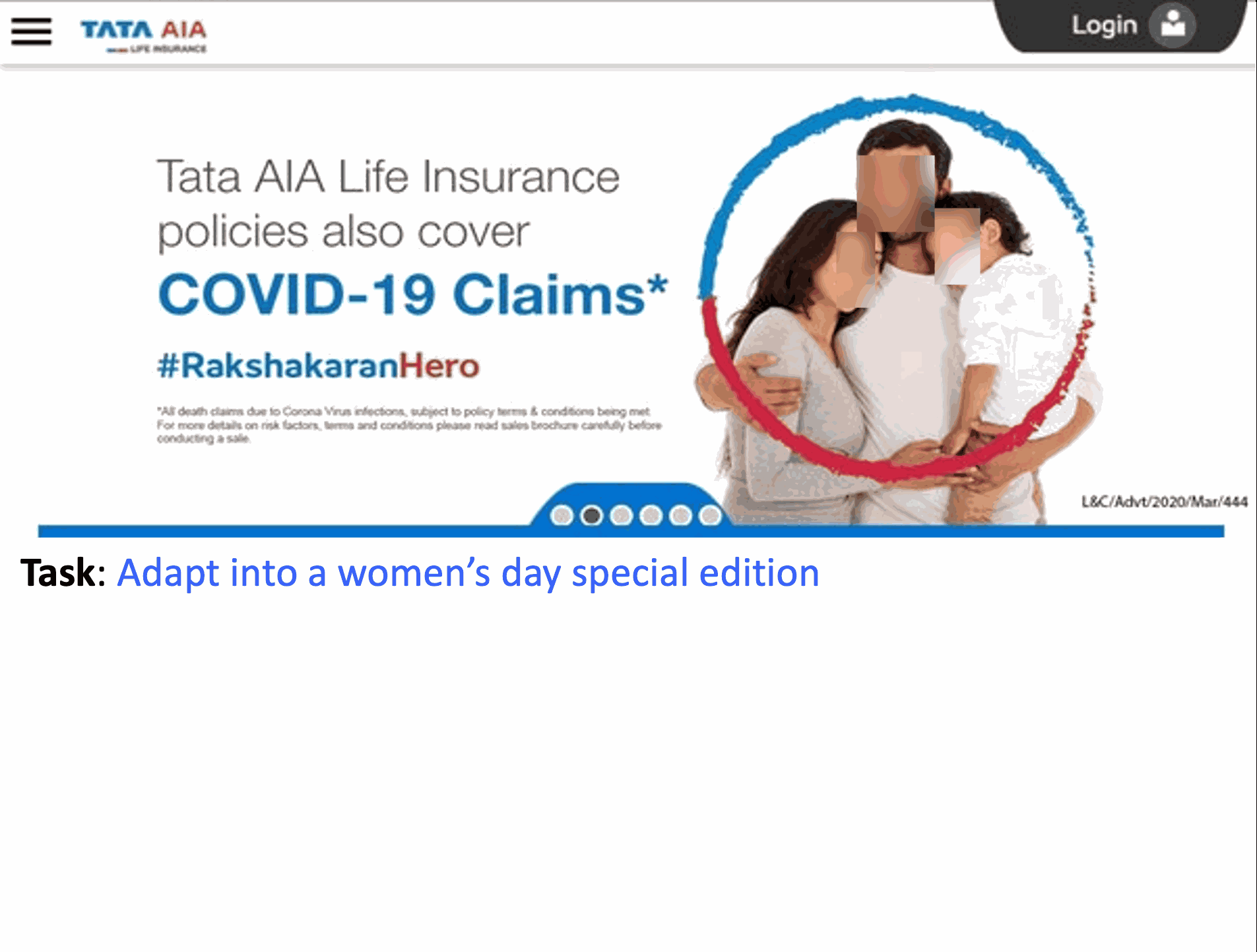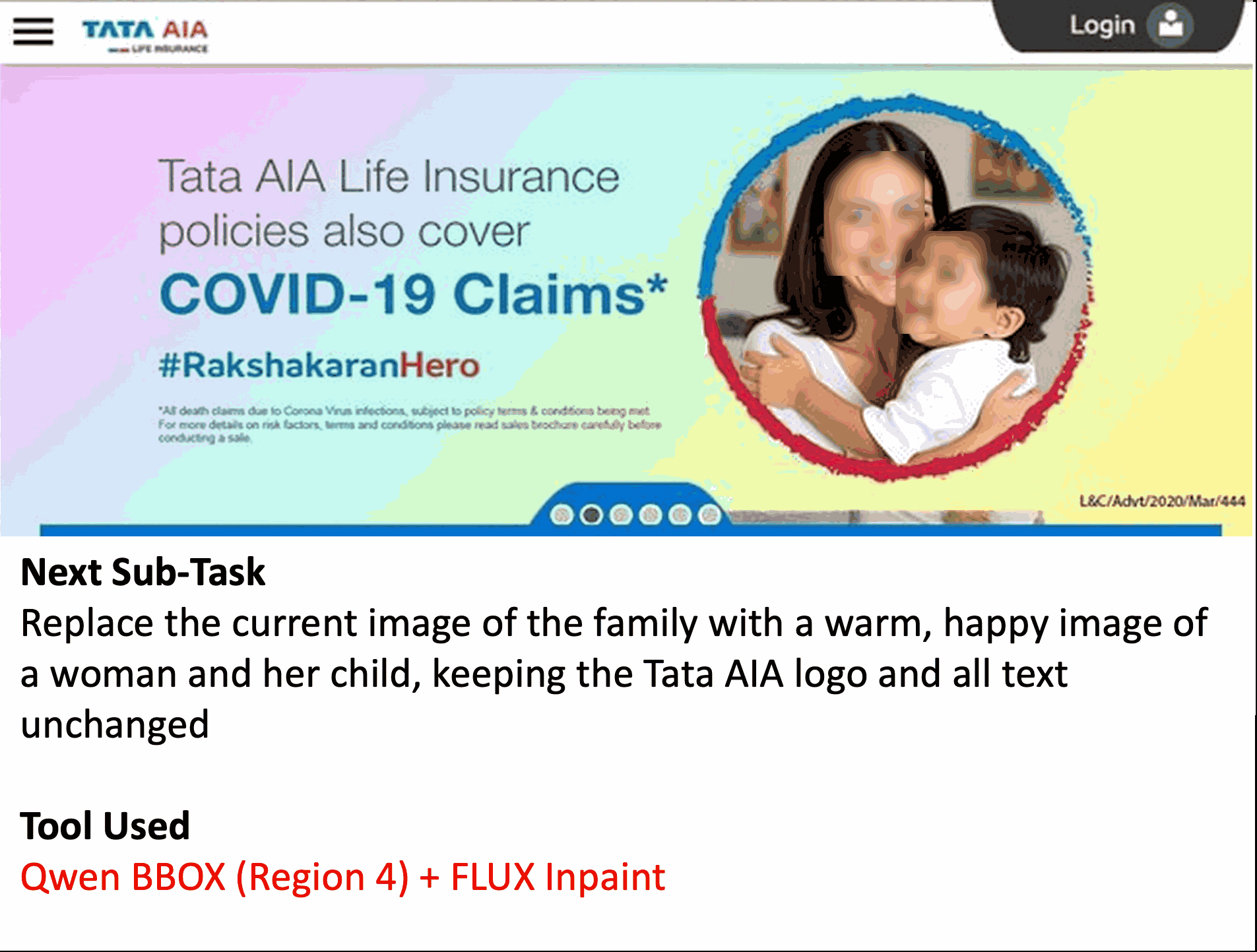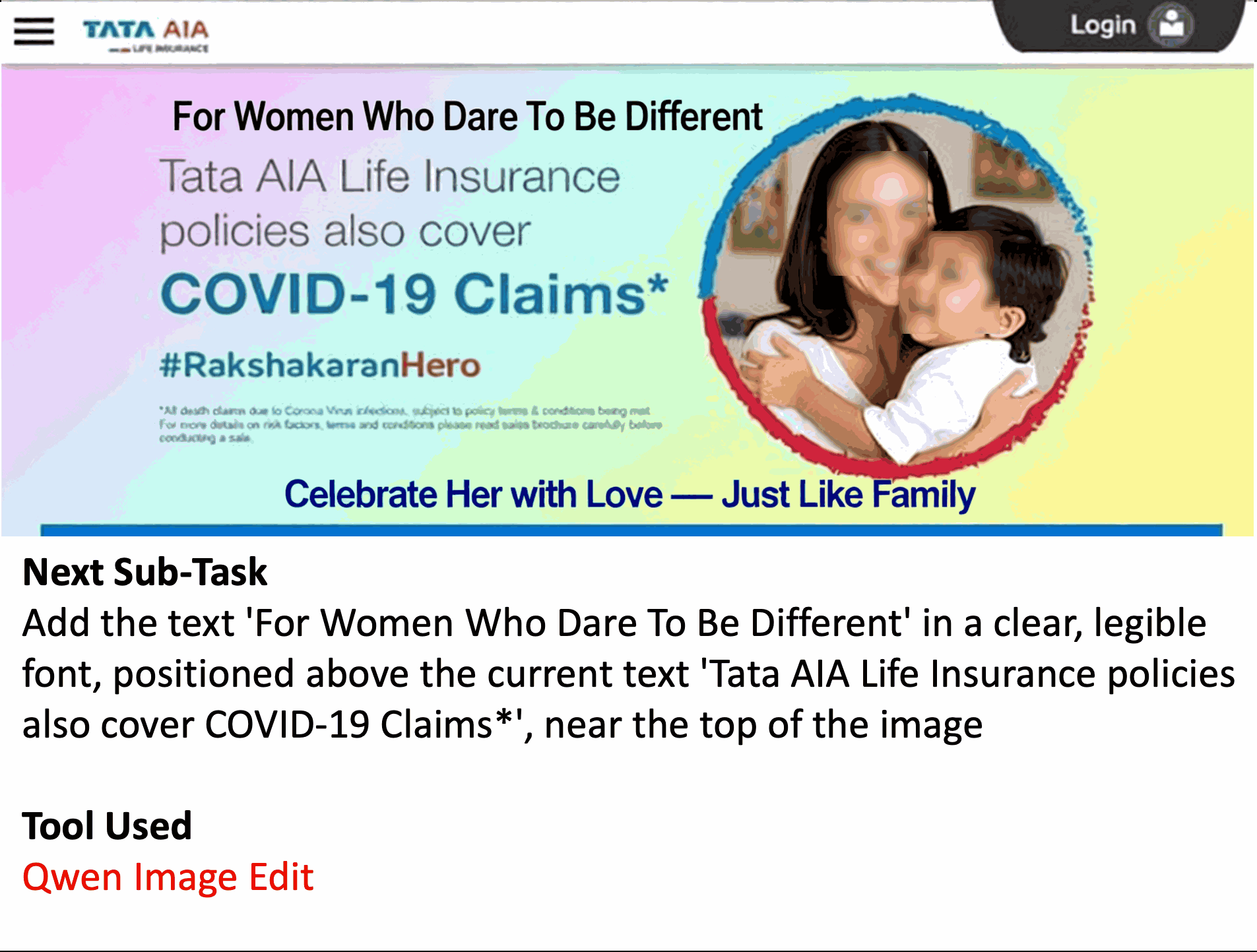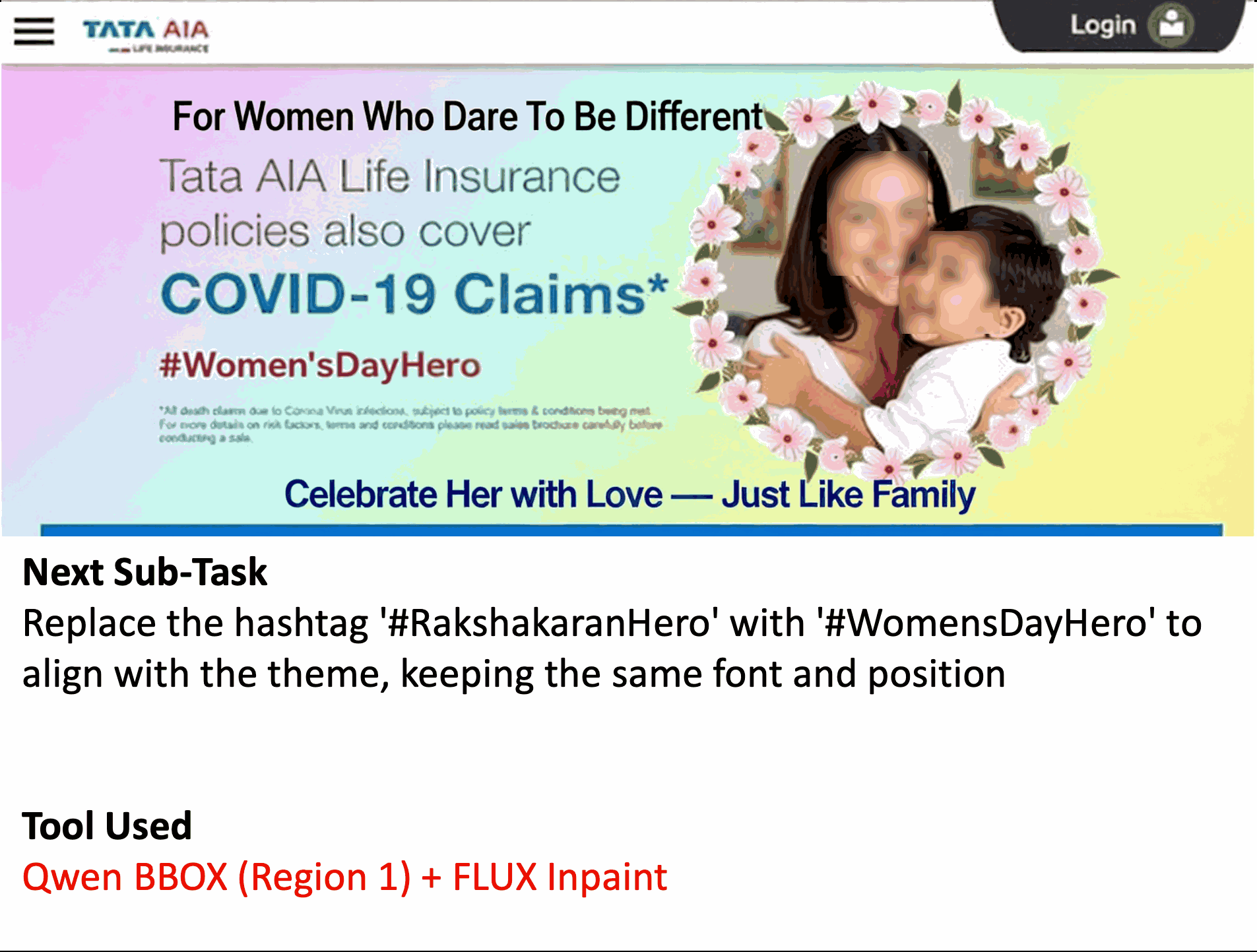
Abstract
Image editing systems are getting very good at making realistic local changes. However, they still struggle when the request is more like an abstract goal than a single concrete edit:
"make this advertisement more eco-friendly."
Such instructions require planning, judgment, and several coordinated transformations rather than a single model invocation.
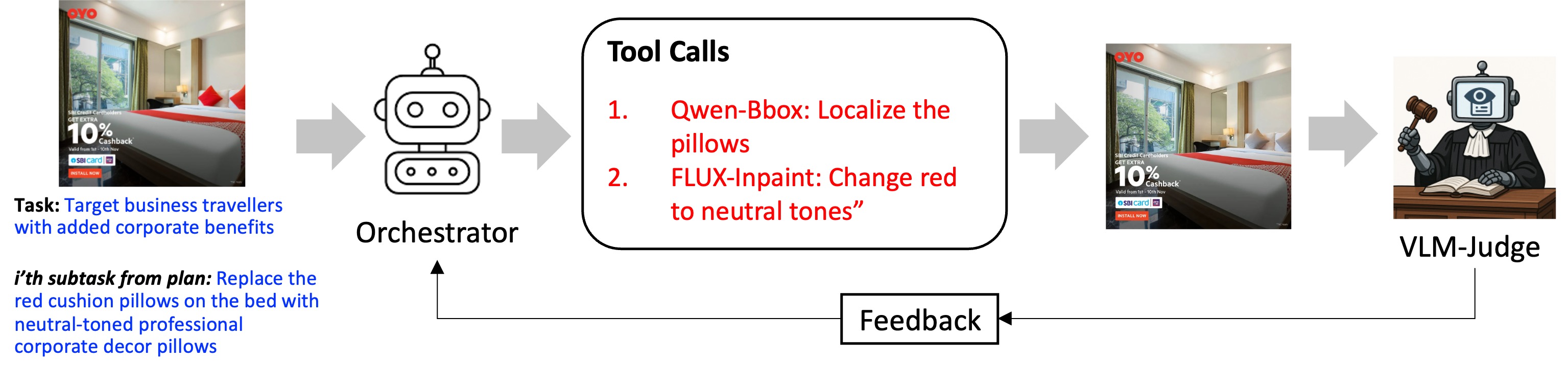
We introduce an agentic tool-calling system for open-ended image editing. A planner breaks the user goal into executable steps, while an orchestrator decides
which tools to use and where to apply them
in the image to satisfy each planned step.
Because these abstract goals do not come with a single prescribed edit sequence, our system learns from experience. After each attempt, a multimodal LLM judge scores whether the result follows the instruction and remains visually plausible; those scores improve the orchestrator. Directly training from exhaustive rollouts is intractable, so we introduce reward approximations that make learning practical.
The result is a system that can handle longer, more open-ended edits and produce
more coherent, reliable visual transformations than single-step or rule-based editing pipelines.
 2.
2.